My research interests focus on developing methods for information retrieval in a multilingual and multi-modal environment and evaluating these methods in how well they support users' access to and use of digital information. I have several distinctive yet related areas of interests: computer-mediated short text conversation, information retrieval under uncertainty, multilingual information access, and e-discovery.
Short Text Conversation
Natural language conversational systems use computer agents to converse with humans in a coherent manner. Such systems can be useful in many application areas, including education, healthcare, government, business, marketing, and social networking where fast and accurate responses to a potentially large number of user inquiries are desired. One of the application areas is the open social media, where people post messages and others follow or respond. The main task of short text conversation here is for computers to automatically generate responses or retrieve messages from historical data and use them as responses. We have looked into the challenges of this task by utilizing topic models generated from machine learning approaches to improve the traditional information retrieval methods. Currently we are expanding the research into other areas, including discussion forums of online courses.
Information Retrieval under Uncertainty
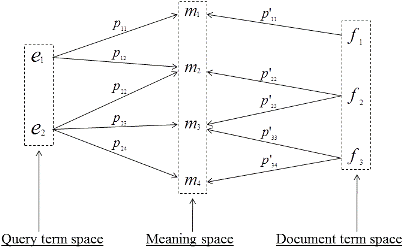
Developing systems, technology, and techniques that can support users' access to multilingual and multimedia information has been of particular interest for both the IR research community and the search engine industry. Cross-language information retrieval (CLIR) is the special task of retrieving documents written in one language in response to queries written in another language. My research on CLIR has focused on statistical approaches that combine bidirectional translation knowledge and synonymy learned from parallel corpora; these approaches belong to a theoretical framework that I call Cross-Language Meaning Matching (CLMM). Experiments with test collections for different language pairs have consistently demonstrated that CLMM results in better CLIR effectiveness than using unidirectional translation knowledge alone, bringing CLIR effectiveness up on par with monolingual retrieval.
CLIR can be viewed as a special case of information retrieval under uncertainty. Another example of information retrieval under uncertainty is Spoken Document Retrieval (SDR). In both cases, the uncertainty lies in the fact that (Statistical) Machine Translation (SMT) or Automatic Speech Recognition (ASR) first generates a set of candidate hypotheses (multiple translations or speech lattices) and then selects one best candidate based on a language model. The best candidate as viewed by the system, however, may not always be the correct one. Such errors are due to the complexity of human languages such as synonymy, homonymy, and polysemy; such errors can degrade retrieval effectiveness significantly. Research on corpus-based CLIR (e.g., CLMM) and lattice-based SDR has shown that using multiple translation/transcription hypotheses and their probabilities as evidence for ranking can improve retrieval effectiveness over using only one best hypothesis; continuous efforts on developing and improving such techniques are clearly needed. The success of these techniques for CLIR and SDR suggests using similar techniques for other types of information retrieval under uncertainty, such as retrieval of scanned documents based on Optical Character Recognition (OCR).
Multilingual Information Access
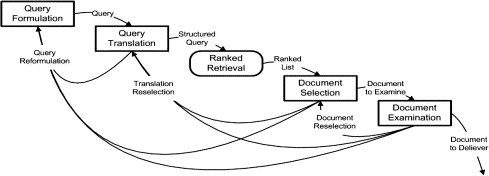
Information access entails the whole process of a user finding information that is relevant to an information need through interacting with a system that manages the information collection. Information access consists of interrelated phases of problem definition, information need elicitation, query formulation, search, document selection and examination, and document delivery. Multilingual information access (MLIA) is more complicated than monolingual information access since users often must interact with noisy translated documents (e.g., for document selection/examination and relevance feedback) and/or noisy translated queries (e.g., for refining queries through translation selection).
The core of MLIA is a system component that indexes documents and matches queries effectively with documents. The problems of MLIA, however, are far more than that. MLIA stands as another area of my research because I'm also interested in other aspects of MLIA beside retrieval algorithms. For example, from a user-system interaction perspective, it is very important to find out whether users can learn to formulate effective queries, whether users can select and examine retrieved documents effectively, how retrieved documents written in different languages should be presented to users, and whether users can understand and use retrieved documents. In an even broader context, the needs of different audiences for multilingual information access and the effects of factors like cross-cultural communication on MLIA need to be explored.
E-Discovery
Another area of my research interest is e-discovery, the retrieval of business documents for the purposes of litigations or government investigations. E-discovery is a challenging task for a variety of reasons. Until recently e-discovery was largely limited to lawyers and paralegal staff, who heavily relied on manual review of documents and keyword-based Boolean searching; systems and technologies developed by the general IR community were much underutilized. In order to build better search technology for e-discovery, IR researchers must first gain a better understanding of the concept of relevance in e-discovery, and that requires collaboration with lawyers to understand legal reasoning and explore the various ways in which a business document can contribute to the building of a legal case.
Modeling relevance in e-discovery is one of the topics I have worked on recently. I have also built experimental systems for studying interactive e-discovery techniques. My hope is that by modeling different types of relevance, we can develop methods for retrieving documents that are relevant to a case in different ways. Furthermore, as more and more business documents are created in different languages and non-text formats, multilingual/multimedia e-discovery will become very important in the near future.
Jianqiang Wang's Research Areas |