IF YOU USE ONE OF THESE SCRIPTS, PLEASE CITE ME.
Spectral Analysis / Phonation Analysis scripts
Get spectral envelope This script extracts long-term average spectra at intervals throughout the sound file. The user specifies the size of each averaged spectrum amplitude bin, e.g. bins of 100 Hz. or 50 Hz., etc. Spectra are calculated dynamically across the duration defined by the textgrid. The number of interval values extracted is equal to the value "numintervals." This is ideal for the analysis of burst spectra (where you would set the interval number to "1") and any other spectral analysis where you wish to plot averaged spectra across different tokens. The picture here below displays a type of output you can generate with different smoothing algorithms applied to the long-term averaged spectra.
![Two averaged spectra of [k] involving different smoothing algorithms. Each represents an average over six tokens.](/~cdicanio/scripts/k_burst_spectra4.png)
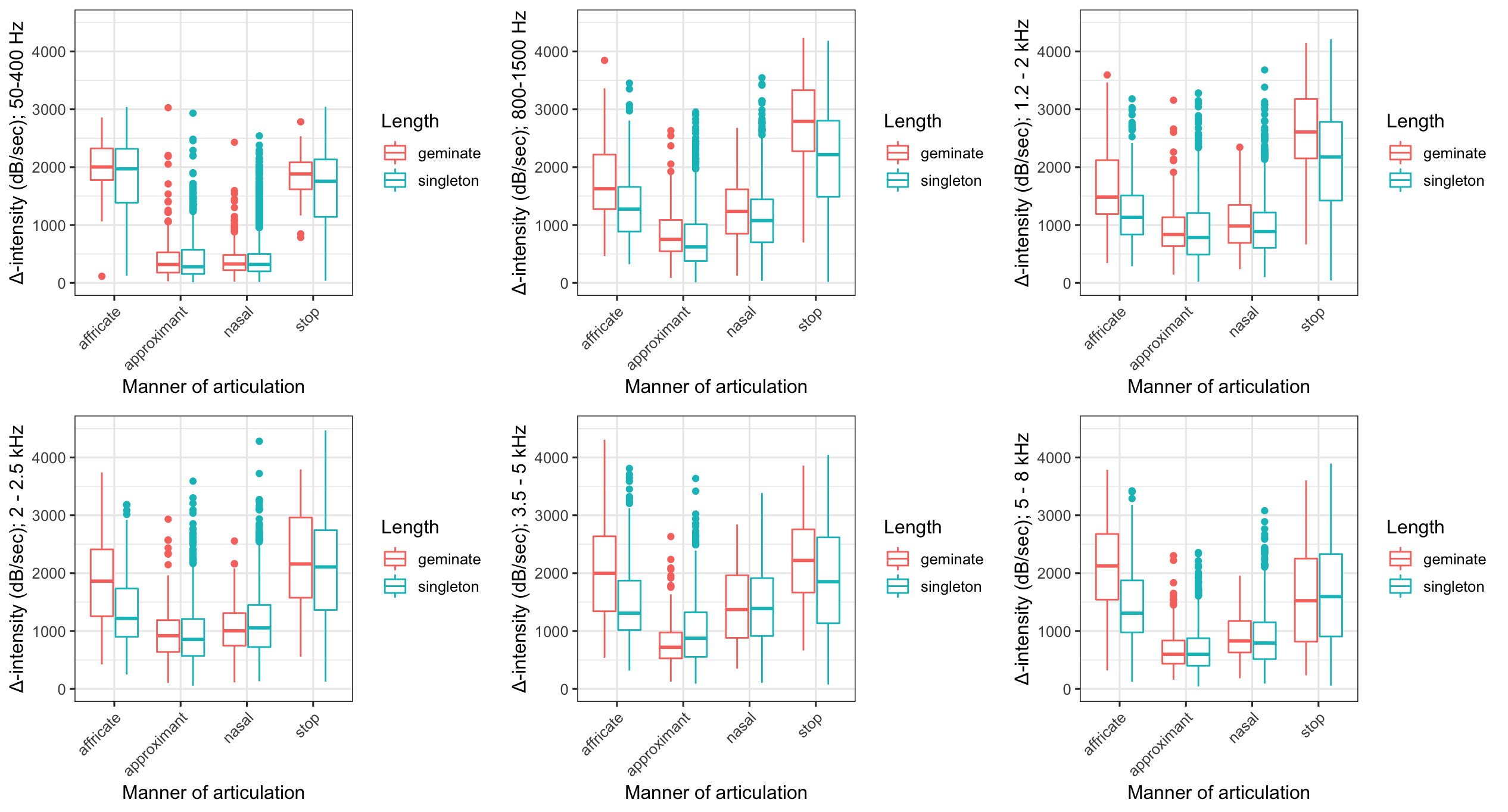
Acoustic measures of obstruent lenition This script is based on a script written by John Kingston in 2008, and featured in Hualde, J. I. and Nadeu, M. (2011). Lenition and phonemic overlap in Rome Italian. Phonetica, 68:215–242. I modified it in 2020 to work with textgrid files of any name across a directory, to permit the script to work only on target segments (not all segments), and to include a number of additional intensity measures at several positions around the consonant target. The user specifies the directory and creates a simple text file in the working directory with each of the labels for the obstruents they wish to examine (each obstruent on a separate line). The script utilizes this information to iteratively extract relative changes in intensity associated with lenition patterns much in the same way as Eric Round's script used in Ennever, T., Meakins, F., and Round, E. R. (2017). A replicable acoustic measure of lenition and the nature of variability in Gurundji stops. Journal of Laboratory Phonology, 8(1):1–32. The code here, however, extracts CV and VC intensity differences and works on existing textgrids with interval tiers (not point tiers). This means that it can be used with normal textgrids and sound files that have been force-aligned. The image below reflects the six frequency bands reflecting local intensity changes associated with singleton and geminate consonants in Itunyoso Triqui (DiCanio and Sharp, submitted). The associated data here is pulled from roughly 2 hours of spontaneous corpus speech that has been force-aligned and corrected.
EGG Open quotient Extraction script for Matlab which prints EGG maxima, EGG minima, DEGG maxima, DEGG minima, Period duration, Open quotient, and Closed quotient. Requires an input directory (input_dur) and an output directory (output_dir). Special thanks to Sam Tilsen.
Formant Script for Praat (time normalized) which extracts F1, F2, and F3 at even intervals in time over the duration of each textgrid-delimited region of a sound file. Works iteratively over a directory.
Formant Script for Praat (not time-normalized) which extracts F1, F2, and F3 at even intervals in time starting from the location of a user-specified interval. Users specify the duration over which they wish to extract formant measures. Works iteratively over a directory.
General vowel acoustics script for Praat (version 2.0) which extracts mean formant values, the first four spectral moments, and F0 dynamically across a duration defined by the textgrid. Duration is also extracted. The number of interval values extracted is equal to the value "numintervals." This script works iteratively across a directory.
Vowel acoustics script for corpus data analysis, v2.0. This script extracts mean formant values, the first four spectral moments, and F0 dynamically across a duration defined by the textgrid. Duration is also extracted. The number of interval values extracted is equal to the value "numintervals." This script works iteratively across a directory and includes contextual information in the output, such as lexical identity, and the preceding/following segment identities.
Spectral Tilt Script for Praat which extracts H1-H2, H1-A1, H1-A2, and H1-A3 at even intervals in time over the duration of each textgrid-delimited region of a sound file. This script also determines pitch and formant values over the same intervals. Recently revised to work iteratively across a directory and to provide HNR values.
Spectral moments of fricative spectra script in Praat which extracts the first four spectral moments (center of gravity, standard deviation, skewness, and kurtosis) as well as the global intensity and duration for each fricative. The DFTs are averaged using time-averaging (Shadle 2012). Within time-averaging, a number of DFTs are taken from across the duration of the fricative. These DFTs are averaged for each token and then the moments are calculated. The user can specify the DFT number, the
DFT window duration, and the low pass filter cut-off (set to 300 Hz., as per Maniwa and Jongman, 2009). The newest version 4.0 was revised in 2021 with extensive help by Wei Rong Chen and Christine Shadle at Haskins Labs. It applies an improved function in calculating the amplitude of frequency bins and does not utilize Praat's built-in functions for spectral moments, but calculates them using methods discussed in Forrest, K., Weismer, G., Milenkovic, P. & Dougall, R. N. (1988) Statistical analysis of word-initial
#voiceless obstruents: preliminary data, Journal of the Acoustical Society of America, 84(1), 115–123.
Duration, Pitch, Intensity, and Rate scripts
Boundary Extractor Script for Praat which extracts the start and end boundaries for all boundaries in a textgrid. This script works iteratively across a directory.Duration Script for Praat which extracts the duration of each textgrid-delimited duration in a sound file.
Speech Rate Script for Praat which prints a syllables per second measure. Requires that there be a textgrid tier with syllables already labelled and another with a label for each repetition in the sound file, e.g. one tier with 5 intervals labelled for 5 repetitions, another with each syllable labelled.
Pitch Dynamics Script for Praat, version 6.2 which provides duration and dynamic F0 values for all files in a directory. In addition to providing these, the F0 maxima and minima and their locations are also calculated. The location of the F0 maxima and minima are normalized. The user can specify the octave jump cost and other variables. If the user has lexemic or syllabic segmentation on additional tiers, this information will also be extracted. New features include the ability to specify the buffer size for F0 tracking and data filtering for excluding short tokens (e.g. less than 50 ms). Version 6 improves memory use in Praat.
Pitch Dynamics for declination data. This script is similar to Pitch Dynamics 5.0 above, though it also tracks utterance and syllable number in a labelled sound file. If the user wishes to examine F0 changes across an utterance, this script is ideal for this purpose.
Cleaning up acoustic files
Convert to one channel. This script will extract just one channel for all sound files in a directory and resave these sound files as mono. Note that this will overwrite your sound files.Rescale intensity peak. This script will rescale the intensity peak for all sound files within a directory to 0.99. Note that this will overwrite your sound files.
Sound file subdivision. This script cuts up a large sound file into smaller chunks using an existing tier on an associated TextGrid file. The assumption of this script is that you have a tier containing only ascii characters which you wish to use as the filename of the smaller file.
Phonetic categorization
Mark rhotics in Praat. This script allows the user to categorize phonetic variants within sound files within the edit window. Upon launching the script, the user observes the rhotic. The user then selects from a floating window how this particular segment is realized. You can replay the sound, zoom in, and examine it as you wish. Right now, the script is organized so that the user specifies the manner/place of articulation, the voicing characteristics, and the position of the rhotic in the word. However, users could essentially use this script to categorize any group of segments - stops, fricatives, vowel types, etc by just modifying the possible options. The output is printed to a log file with numbers associated with each category.
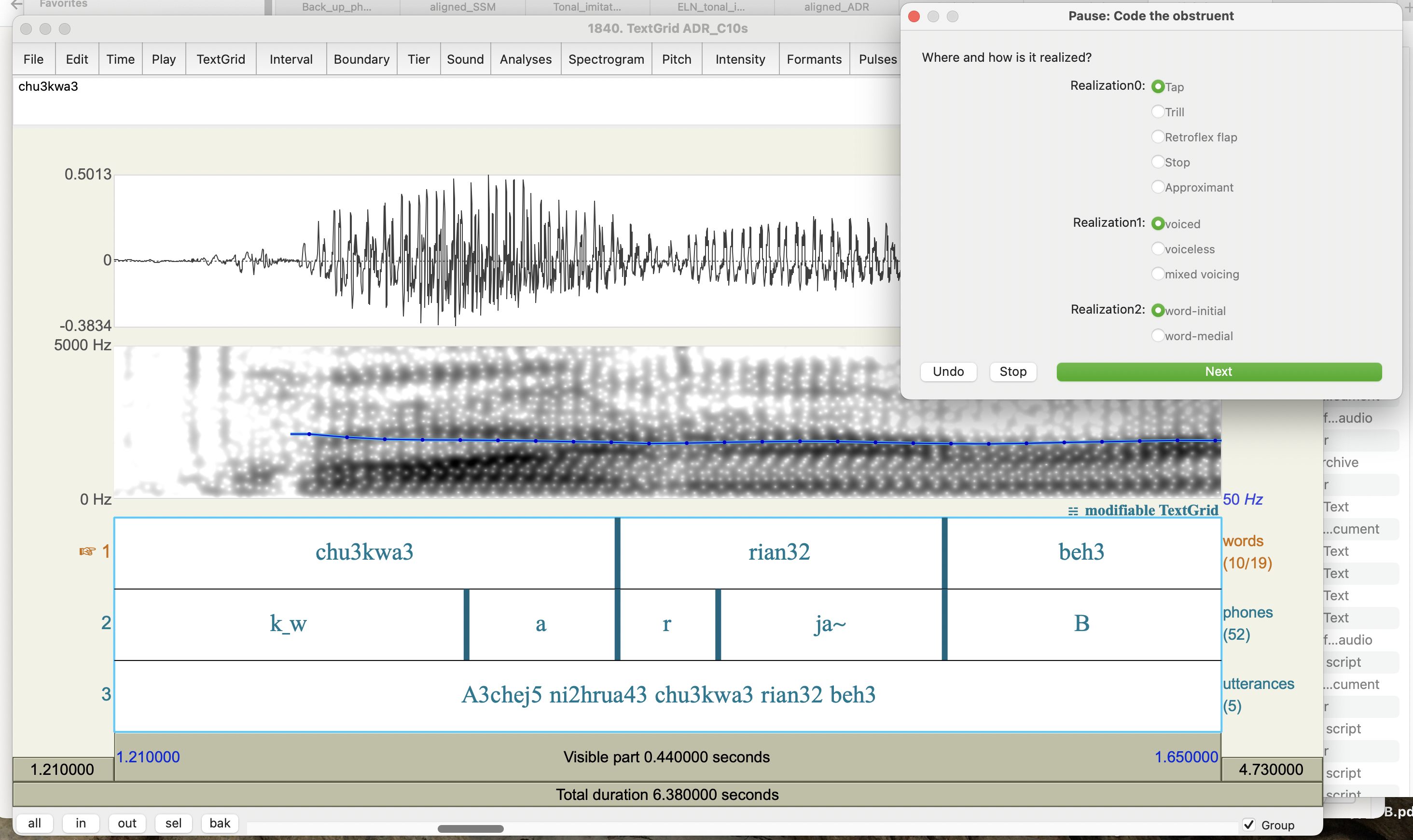
Mark glottalization in Praat. This script allows the user to categorize phonetic variants within sound files within the edit window. Upon launching the script, the user observes a segment in question in an aligned textgrid, e.g. a glottal stop. The user then selects from a floating window how this particular segment is realized. Right now, the script is organized so that the user specifies both the position of the segment in the word (Position) and the realization of the glottal stop (Realization) among a set of fixed options. However, users could essentially use this script to categorize any group of segments - stops, fricatives, vowel types, etc by just modifying the possible options on lines 70 and 78. The script requires that the user create a simple text file containing the list of all the segments they wish to categorize, with each segment on separate lines.
TextGrid modification scripts
Eliminate tiers. This script eliminates a specific tier for all textgrids in a directory. This is useful for things like forced alignment.Combine/Merge intervals in Praat. This script allows the user to merge any two adjacent intervals in a TextGrid and relabel them.
Insert VOT components for stops in Praat. This script reads a textgrid file and creates a tier with component labels for stop consonants. Four components may be included, e.g. voiced closure duration, voiceless closure duration, release burst, and aspiration. However, the user can specify whatever names they prefer for each. This script requires that there already be a segmentation of the speech signal into phone-sized units. Note that this script does not segment stops into components. It simply puts the labels down on an interval tier for the user to more easily do it her/himself. This script requires a simple text file with each of the stops on a separate line. An example can be found here.
Insert VOT components for stops in Praat (3 components). This is identical to the script above but assumes the stop will be split into 3 components instead of four.
Silent Replacement Script for Praat. For all portions of a textgrid which have no label, this script replaces the portion with absolute silence (zero amplitude). This script is useful for anyone wanting to "clean up" sound files which have additional unwanted information in the recording.
Text Replacement Script for Praat. For all portions of a textgrid which have label x, this script replaces the label with y. If you wish to replace labeled portions with no label or unlabeled portions with a label, use two double quotations for the unlabeled interval.
Add points from intervals. This script takes an interval tier in a Praat textgrid and creates a point tier for those labels which the user specifies in a separate file, e.g. obstruents.txt. The new point tier is labeled 'Origins' for use with Eric Round's suite of lenition encoding scripts. The user must create a text file where each obstruent (or whatever set of sounds they wish to place on a point tier) on a separate line. This external file must be in the same directory as the textgrids which are modified with this script.