Exercise 1: Scrape Webpage using 'split and select'¶
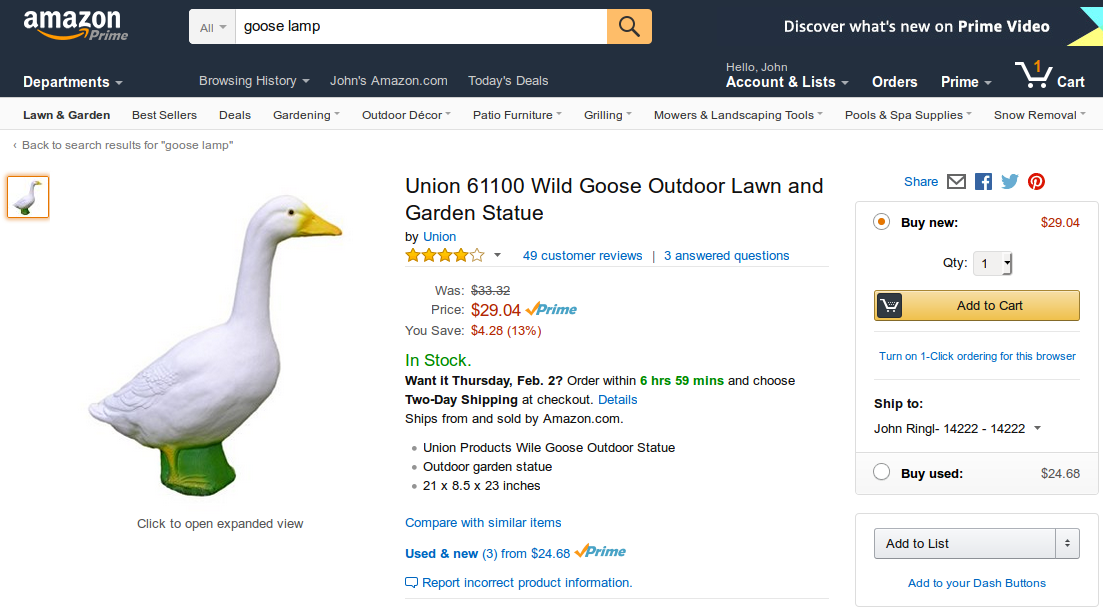
Our goal is to scrape the price of products on Amazon including¶
https://www.amazon.com/Union-61100-Outdoor-Garden-Statue/dp/B0027YPQEC¶
In [6]:
s = open('class1_files/gooselamp.html').read()
s[0:1000]
Out[6]:
In [7]:
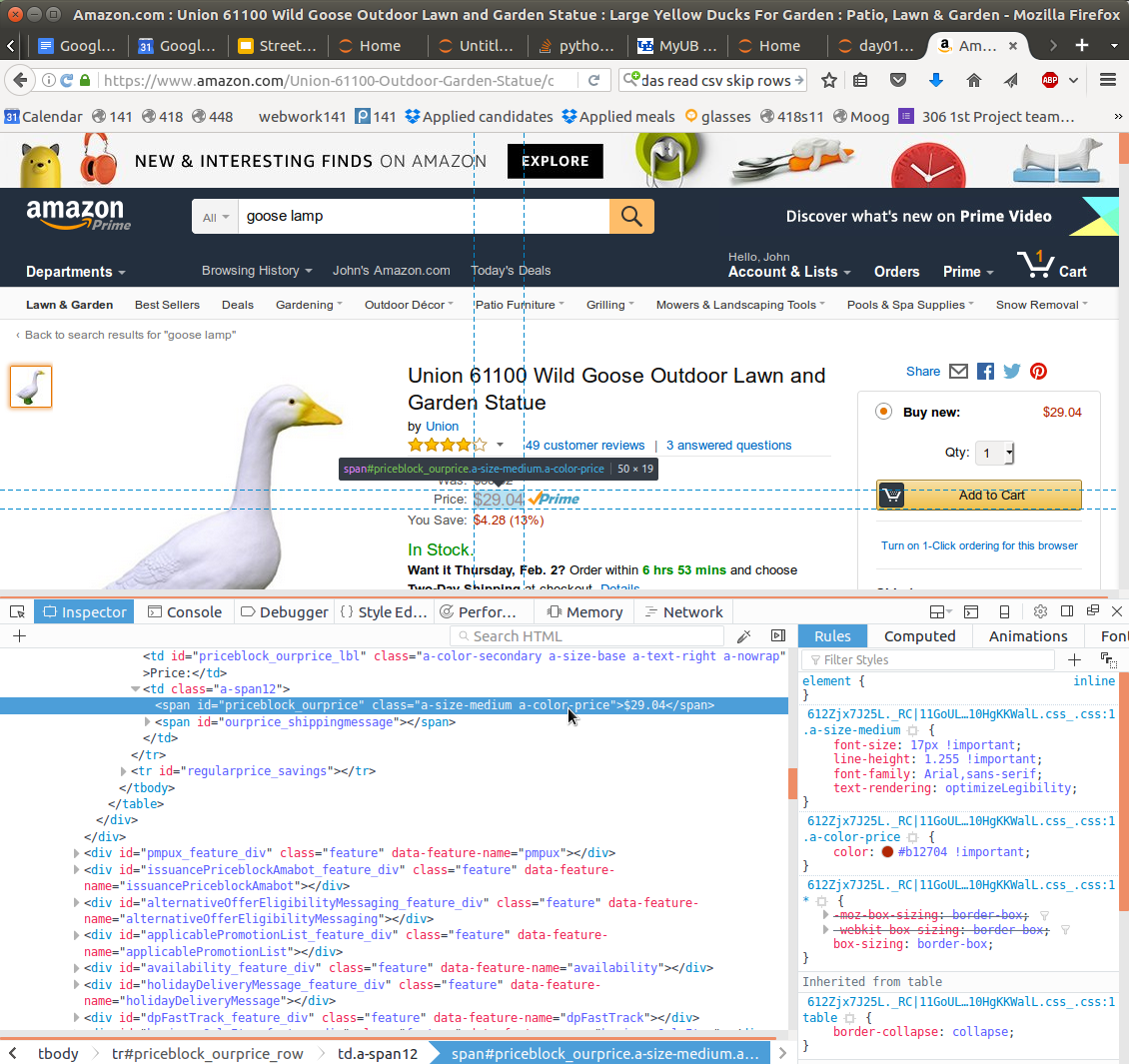
l1 = s.split('<span id="priceblock_ourprice" class="a-size-medium a-color-price">$')
len(l1)
Out[7]:
In [8]:
l1[0][:1000]
Out[8]:
In [9]:
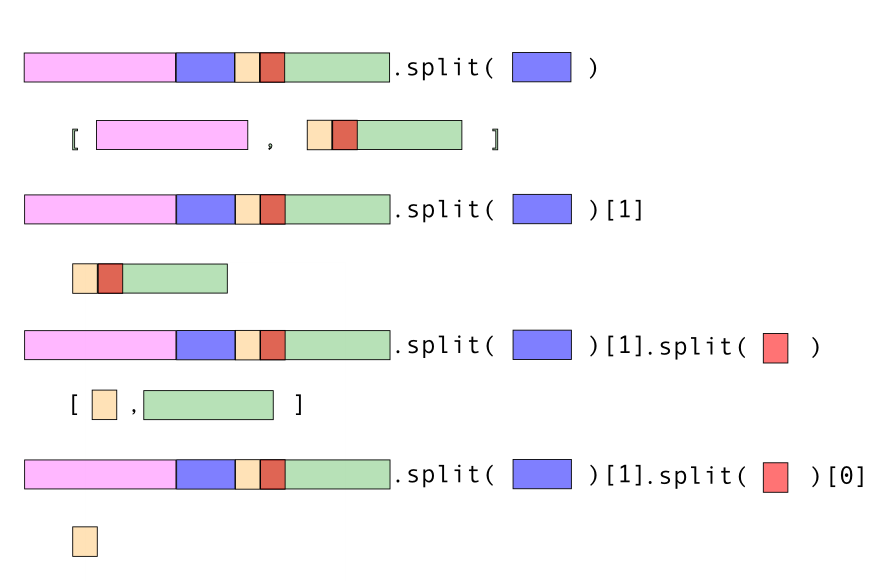
price = l1[1].split('</span>')[0]
price
Out[9]:
In [10]:
price = float(l1[1].split('</span>')[0])
price
Out[10]:
In [11]:
# In summary
s = open('class1_files/gooselamp.html').read()
l1 = s.split('<span id="priceblock_ourprice" class="a-size-medium a-color-price">$')
price = float(l1[1].split('</span>')[0])
price
Out[11]:
Now lets access the real webpage, and not the downloaded html file¶
In [12]:
import requests
url = 'https://www.amazon.com/Union-61100-Outdoor-Garden-Statue/dp/B0027YPQEC'
s = requests.get(url)
'19.59' in s.text
#if this returns true, then you've successfully accessed the webpage and it does in fact contain the string `19.59'
Out[12]:
Oh, it actually worked. Sometimes you will find Amazon refuses to serve the page to a script (robot). In that case, we will need to fake our User Agent.¶
see https://www.whoishostingthis.com/tools/user-agent/ for more info¶
In [13]:
url = 'http://math.buffalo.edu'
s = requests.get(url)
# print(s.text)
In [14]:
url = 'http://www.buffalo.edu/cas/math.html'
s = requests.get(url,headers={'User-Agent':'Fake out!'})
In [15]:
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'
s = requests.get(url,headers={'User-Agent':'Fake out!'})
s.text[1:100]
Out[15]:
Finally, we can wrap everything up in a function that can retrieve the price of any product:¶
In [16]:
import requests
def getprice(pid):
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'
url = 'https://www.amazon.com/dp/'+pid
s = requests.get(url, headers={'User-Agent':ua})
pattern = '<span id="priceblock_ourprice" class="a-size-medium a-color-price">$'
price = float( s.text.split(pattern)[-1].split('</span>')[0] )
return price
price = getprice('B0027YPQEC')
print(price)
In [17]:
pid = 'B00BB581NQ'
url = 'https://www.amazon.com/dp/'+pid
price = getprice(pid) # another item: a kite
print('the price of item ' + url + ' is ' + str(price) )